NOIP2013年普及组初赛题目及答案分析
一、单项选择题
1. 一个 32 位整型变量占用( A )个字节。
A. 4 B. 8 C. 32 D. 128
【分析】32位整型,1Byte=8位, 32/8=4,答案选A
2.二进制数 11.01 在十进制下是( A )。
A. 3.25 B. 4.125 C. 6.25 D. 11.125
【分析】二进制转十进制,按权展开即可。 1*21+1*20+0*2-1+1*2-2=3.25
3.下面的故事与( B )算法有着异曲同工之妙。 从前有座山,山里有座庙,庙里有个老和尚在给小和尚讲故事:从前有座山,山里有座庙,庙里有个老和尚在给小和尚讲故事:‘从前有座山,山里有座庙,庙里有个老和尚给小和尚讲故事….’
A. 枚举 B. 递归 C. 贪心 D. 分治
【分析】
A选项枚举法是一个一个挨个尝试的方法,B递归是自己调用自己,C贪心是从局部开始考虑出一个解,只是局部最优解,不一定是全局最优解。D分治是把大的问题化成小的,分而治之的思想。
4.逻辑表达式( C )的值与变量A 的真假无关。
A. (A ∨ B) ∧﹃A
B. (A ∨ B) ∧﹃B
C. (A ∧ B) ∨ (﹃ A ∧ B)
D. (A ∨ B) ∧﹃A ∧ B
【分析】
题目中描述的与变量A的真假无关的意思是不论B的值是多少,改变A变量的真假,不会影响到最后结果。 这样的题目可以每种情况列举一下。
A 选项, 先选定B为真,当A为真,结果是假,当A为假时,结果是真。A排除。
B 选项,先选定B为真,当A为真,结果是假,当A为假时,结果为假。 然后选定B为假,当A为真时,结果为真,当A为假时,结果为假。B排除
C 选项,先选定B为真,当A为真时,结果为真,当A为假时,结果为真。然后选定B为假,当A为真时,结果是假,当A为假时,结果为假。选C
D选项,先选定B为真,当A为真时,结果为假,当A为假时,结果为真,D排除。
5.将( 2, 6, 10, 17)分别存储到某个地址区间为0~10 的哈希表中,如果哈希函数h(x) = ( D ),将不会产生冲突,其中a mod b 表示 a 除以 b 的余数。
A. x mod 11 B. x2 mod 11
C. 2x mod 11 D. |√2| mod 11 ,其中√X表示√X下取整
【分析】首先明确一个概念,哈希冲突是不同K值产生的相同冲突。
A选项, x mode 11 。 2 mod 11 =2 , 6 mod 11 = 6, 10 mod 11 =10, 17 mod 11 = 6 。出现了重复的值。
B选项 ,
6.在十六进制表示法中,字母 A 相当于十进制中的( B )。
A. 9 B. 10 C. 15 D. 16
【分析】十六进制中的A相当于十进制中的10
7.下图中所使用的数据结构是(B )。
A. 哈希表 B. 栈 C. 队列 D. 二叉树
【分析】数据先进后出,是栈。
8.在 Windows 资源管理器中,用鼠标右键单击一个文件时,会出现一个名为“复制”的操作选项,它的意思是( C )。
A. 用剪切板中的文件替换该文件
B. 在该文件所在文件夹中,将该文件克隆一份
C. 将该文件复制到剪切板,并保留原文件
D. 将该文件复制到剪切板,并删除原文件
【分析】复制的意思是先将文件复制到剪贴板,并保留原文件,因为我们可以一次复制,多次粘贴。
9.已知一棵二叉树有10 个节点,则其中至多有( A)个节点有 2 个子节点。
A. 4 B. 5 C. 6 D. 7
【分析】我们设 N0,N1,N2分别为度为0的点,度为1的点,度为2点。根据公式:
N0+N1+N2=10; 因为 N0=N2+1, 得N1+2N2=9。根据定律N1只能是0或1
根据题意N1只能是1,所以N2是4。
在一个无向图中,如果任意两点之间都存在路径相连,则称其为连通图。下图是一个有4 个顶点、 6 条边的连通图。若要使它不再是连通图,至少要删去其中的( C )条边。
A. 1 B.2 C. 3 D. 4
【分析】联通图的定义:在无向图中,任意两个顶点之间能够联通。要让联通图不再联通,只要孤立出一个顶点即可,题目中的图孤立出一个点之后就是去点3条线。
11.二叉树的( A)第一个访问的节点是根节点。
A. 先序遍历 B. 中序遍历 C. 后序遍历 D. 以上都是
【分析】先序遍历是“根左右”,中序遍历“左根右”,后序遍历“左右根”
12.以 A0 作为起点,对下面的无向图进行深度优先遍历时,遍历顺序不可能是( A)。
A. A0, A1 , A2, A3
B. A0, A1, A3, A2
C. A0, A2, A1, A3
D. A0, A3, A1, A2
【分析】深度优先遍历是从起点开始走到下一个顶点,当来到一个标记过的顶点时退回顶点,再选择一条没有到达的顶点。所以有以下4种,
【A0,A1,A3, A2 】 【A0, A3,A1,A2】 【A0, A2 , A1 , A3】 【A0, A2 ,A3 ,A1】。不可能出现A选项。
13.IPv4 协议使用32 位地址,随着其不断被分配,地址资源日趋枯竭。因此,它正逐渐被使用( D )位地址的 IPv6 协议所取代。
A. 40 B. 48 C. 64 D. 128
【分析】IPv4是32位,IPv6是128位地址。
14.( A)的 平均时间复杂度为 O(n log n),其中 n 是待排序的元素个数。
A. 快速排序 B. 插入排序 C. 冒泡排序 D. 基数排序
【分析】快速排序的平均时间复杂度O(n log n), 插入排序的平均时间复杂度是O($N^2$),冒泡排序的平均时间复杂度是O($N^2$),基数排序的时间复杂度是O(N*k)。
15.下面是根据欧几里得算法编写的函数,它所计算的是 a 和 b 的(A)。
int euclid(int a, int b)
{
if (b == 0)
return a;
else
return euclid(b, a % b);
}A. 最大公共质因子 B. 最小公共质因子 C. 最大公约数 D. 最小公倍数
【分析】欧几里得算法是求最大公约数。如果不确定就直接举例,比如6 ,3。第一次返回的是(3,0),结果就是3,是6和3的最大公约数。
16.通常在搜索引擎中,对某个关键词加上双引号表示( C )。
A. 排除关键词,不显示任何包含该关键词的结果
B. 将关键词分解,在搜索结果中必须包含其中的一部分
C. 精确搜索,只显示包含整个关键词的结果
D. 站内搜索,只显示关键词所指向网站的内容
【分析】精确搜索,就是在关键词外加双引号,例如 “体育运动”。排除搜索,就是在结果中排序某个选项,例如“体育运动”-篮球。或逻辑,只有在两个关键词中间加OR即可,表示两个关键词相关的结果。站内搜索,只队某个站内的信息进行搜索,只需要加上冒号和后面的站名就可以。比如 篮球:baidu.com
17.中国的国家顶级域名是(A )。
A. .cn B. .ch C. .chn D. .china
【分析】中国的顶级域名是cn, 美国的是us
18.把 64 位非零浮点数强制转换成32 位浮点数后, 不可能 ( D )。
A. 大于原数 B. 小于原数 C. 等于原数 D. 与原数符号相反
【分析】非零浮点数强制转成32位后,有可能比原数大或比原数小,也有可能比原数小,但是绝对不可能出现跟原数符号相反的情况。
19.下列程序中,正确计算1, 2, ?, 100 这 100 个自然数之和 sum(初始值为0)的是(A )。
A.
i =1;
do{
sum+=i;
i++;
}while(i<=100);B.
i=1;
do{
sum+=i;
i++;
}while(i>100);C.
i=1;
while(i<100){
sum+=i;
i++;
}D.
i=1;
while(i>=100){
sum+=i;
i++;
}【分析】A选项是计算1加到100,B选项i>100这个条件不会加到100的。C选项只能加到99,D选项i>=100,条件不会成立。
20.CCF NOIP 复赛全国统一评测时使用的系统软件是(B )。
A. NOI Windows B. NOI Linux C. NOI Mac OS D. NOI DOS
【分析】NOI linux是官方的评测系统 。
二、问题求解
7 个同学围坐一圈,要选 2 个不相邻的作为代表,有____14____种不同的选法。
【分析】可以反向考虑,把所有两个人的情况减去相邻的情况。
C(7,2)-7=14, 其中C(7,2)是7个人中,选出2个人的不同的组合,然后减去下面这7种相邻的就是不相邻的情况。
2.某系统自称使用了一种防窃听的方式验证用户密码。密码是n 个数 s1, s2, ? , sn,均为 0或 1。该系统每次随机生成 n 个数 a1, a2, ? , an,均为 0或1,请用户回答 (s1a1 + s2a2 + ?+ snan) 除以 2 的余数。如果多次的回答总是正确,即认为掌握密码。该系统认为,即使问答的过程被泄露,也无助于破解密码——因为用户并没有直接发送密码。 然而,事与愿违。例如,当n = 4 时,有人窃听了以下5 次问答:
就破解出了密码 s1 = ___0___,s2 =___1___ ,s3 =___1______ ,s4 =______1___
【分析】
根据题意s1*a1+s2*a2+......+ 这个是方程的思想,我们直接带入这个可以得到以下5个方程。
(s1+s2)%2=1 (1式)
(s3+s4)%2=0 (2式)
(s2+s3)%2=0 (3式)
(s1+s2+s3)%2=0 (4式)
s1%2=0 (5式)
由5式得,s1一定是0,那么1式中 s2一定是1。根据s2是1,带入3式,那么s3是1,根据s3是1,带入2式,那么s4是1。
三、阅读程序写结果
1.
#include<iostream> using namespace std; int main() { int a,b; cin>>a>>b; cout<<a<<"+"<<b<<"="<<a+b<<endl; return 0; }输入: 3 5 输出: 3+5=8
【分析】送分题,3+5=8,容易疏忽的一点是要输出过程,不能只写结果。
2.
#include<iostream> using namespace std; int main() { int a,b,u,i,num; cin>>a>>b>>u; num=0; for(i=a;i<=b;i++) if((i%u==0)) num++; cout<<num<<endl; return 0; }输入: 1 100 15 输出: _____6________
【分析】题目的含义是a到b的范围内能对u整除的数个数。
当i=15,30,45,50,75,90的时候,if条件成立,所以一共计数6次。
3.
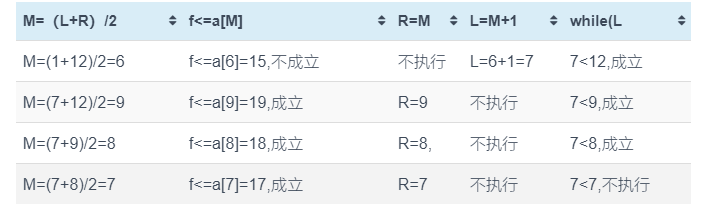
#include <iostream> using namespace std; int main() { const int SIZE = 100; int n, f, i, left, right, middle, a[SIZE]; cin>>n>>f; for (i = 1; i <= n; i++) cin>>a[i]; left = 1; right = n; do { middle = (left + right) / 2; if (f <= a[middle]) right = middle; else left = middle + 1; } while (left < right); cout<<left<<endl; return 0; }输入: 12 17
2 4 6 9 11 15 17 18 19 20 21 25
输出: _____7_____
【分析】考察二分法。
初始状态left=1,right=n=12,f=17,用L表示left,R表示right,M表示middle
{kind=link}
4.
#include <iostream> using namespace std; int main() { const int SIZE = 100; int height[SIZE], num[SIZE], n, ans; cin>>n; for (int i = 0; i < n; i++) { cin>>height[i]; num[i] = 1; for (int j = 0; j < i; j++) { if ((height[j] < height[i]) && (num[j] >= num[i])) num[i] = num[j]+1; } } ans = 0; for (int i = 0; i < n; i++) { if (num[i] > ans) ans = num[i]; } cout<<ans<<endl; }输入:
6 2 5 3 11 12 4
输出: 4
【分析】最长上升子序列。
一个双重for循环的判断与计数,仔细一点分清即可。初始值n=6,为了简单起见,用h[ ]表示height[ ]数组 ,用n[ ]表示num[ ]数组,题目中没有被修改过,所以先记录下来h[0]=2, h[1]=5 , h[2]=3, h[3]=11,h[4]=12, h[5]=4
| 外层for | n[i] | 内层for | h[j]<h[i] | n[j]>=n[i] | n[j]+1 | n[i] |
| i=0 | n[0]=1 | j=0,j<i,false | x | x | x | x |
| i=1 | n[1]=1 | j=0,j<i,true | h[0]<h[1],true | n[0]>=n[1],true | n[0]+1 | 2 |
| j=1,j<i,false | ||||||
| i=2 | n[2]=1 | j=0,j<i,true | h[0]<h[2],true | n[0]>=n[2],true | n[0]+1 | 2 |
| j=1,j<i,true | h[1]<h[2],false | x | x | x | ||
| j=2,j<i,false | x | x | x | x | ||
| i=3 | n[3]=1 | j=0,j<i,true | h[0]<h[3],true | n[0]>=n[3],true | n[0]+1 | 2 |
| j=1,j<i,true | h[1]<h[3],true | n[1]>=n[3],true | n[1]+1 | 3 | ||
| j=2,j<i,true | h[2]<h[3],true | n[2]>=n[3],false | x | x | ||
| j=3,j<i,false | x | x | x | x | ||
| i=4 | n[4]=1 | j=0,j<i,true | h[0]<h[4],true | n[0]>=n[4],true | n[0]+1 | 2 |
| j=1,j<i,true | h[1]<h[4],true | n[1]>=n[4],true | n[1]+1 | 3 | ||
| j=2,j<i,true | h[2]<h[4],true | n[2]>=n[4],false | x | x | ||
| j=3,j<i,true | h[3]<h[4],true | n[3]>=n[4],true | n[3]+1 | 4 | ||
| j=4,j<i,false | x | x | x | x | ||
| i=5 | n[5]=1 | j=0,j<i,true | h[0]<h[5],true | n[0]>=n[5],true | n[0]+1 | 2 |
| j=1,j<i,true | h[1]<h[5],false | x | x | x | ||
| j=2,j<i,true | h[2]<h[5],false | x | x | x | ||
| j=3,j<i,true | h[3]<h[5],false | x | x | x | ||
| j=4,j<i,true | h[4]<h[5],false | x | x | x | ||
| j=5,j<i,false | x | x | x | x |
双重for循环是数据之间两两比较。后者比前者大的数据才能成立,成立后去更新n数组的值。最后一个for循环是找出n数组的最大值。
四、完善程序
(序列重排)全局数组变量 a 定义如下:
const int SIZE =100;
int a[SIZE],n;
它记录着一个长度为n的序列 a[1] , a[2] , ? a[n]。 现在需要一个函数,以整数p(1<=p<=n)为参数,实现如下功能:将序列a的前p个数与后n-p个数对调,且不改变着p个数(p或n-p个数)之间的相对位置。例如,长度为5的序列 1,2,3,4,5。当p=2时重排结果为3,4,5,1,2。 有一种朴素的算法可以实现这一需求,其时间负复杂度为O(n)、空间复杂度为O(n);
void swap1(int p) { int i,j,b[SIZE]; for(i=1,i<=p;i++) b[ ① ]=a[i]; for(i=p+1;i<=n;i++) b[i-p]= ② ; for(i=1;i<= ③ ;i++) a[i]=b[i]; }我们也可以用时间换空间,使用时间复杂度为O(n2)、空间复杂度为O(1)的算法:
void swap2(int p) { int i,j,temp; for(i=p+1;i<=n;i++) { temp=a[i]; for(j=i;j>= ④ ; j--) a[j]=a[j-1]; ⑤=temp; } }【分析】
整体思路,先把a数组的前p个数放到b数组的后面部分,再把a数组的后p个数放到b数组的前面部分。
①:【 n-p+1 】 解释,循环从i到p,把前i个数给p数组的后面部分,所以是n-p,数组从1开始,所以n-p+1
②:【 a[i] 】 解释,循环从p+1开始,把a数组后面的数放前面
③:【 n 】 送分题,解释,前面已经把数组全部造好了,这个地方后面的语句是把b数组赋值给a数组,所以是n
④:【 i-p+1 】 解释,第二种方法是从p+1到n,先把值给temp,然后统一挪动a数组的值(i的初值是p+1,此处要大于i-p+1,)
⑤:【 a[i-p] 】解释,内部for循环执行完毕后,把当前temp的值赋值给挪动后的数组位置
2.(二叉查找树) 二叉查找树具有如下性质:每个节点的值都大于其左子树上所有节点的值、小于其右子树上所有节点的值。试判断一棵树是否为二叉查找树。
输入的第一行包含一个整数 n, 表示这棵树有n个顶点,编号分别为1,2,?,n,其中编号为1的为根结点,之后的第i行有三个数,value,left_child,right_child,分别表示改节点关键字的值、左子节点编号、右子节点编号;如果不存在左子节点或右子节点,则用0代替。输出1表示这棵树是二叉查找树,输出0则表示不是。
#include<iostream> using namespace std; const int SIZE=100; const INFINITE=1000000; struct node{ int left_child,right_child,value; }; node a[SIZE]; int is_bst(int root, int lower_bound,int upper_bound) { int cur; if(root==0) return 1; cur=a[root].value; if((cur>lower_bound) && ( ①) && (is_bst(a[root].left_child,lower_bound,cur )==1) && (is_bst( ②、③、④)==1) return 1; return 0; } int main() { int i,n; cin>>n; for(i=1;i<=n;i++) cin>>a[i].value>>a[i].left_child>>a[i].right_child; cout<<is_bst( ⑤ ,-INFINITE,INFINITE)<<endl; return 0; }【分析】 二叉查找树的整体思路:
若根结点的关键字值等于查找的关键字,成功。否则,若小于根结点的关键字值,递归查找左子树。若大于根结点的关键字值,递归查右子树。若子树为空,查找不成功。
从代码中分析,is_bst函数是一个递归函数的参数有三个,root是根节点,lower_bound是所有左子树的值,upper_bound是所有右子树的值。函数不断递归修改这三个参数。
①:【 cur< upper_bound 】 解释,根据题目要求,这个地方返回值是1,所以说明是二叉查找树,前面已经给了cur>lower_bound了,这个地方就应该是cur<upper_dound
②:【 a[root].right_child 】 解释,上面是递归左子树,这个地方应该是递归右子树
③:【 cur 】 解释,右子树变成当前的根节点,cur(就是原来的根节点值)变成了lower_bound,
④:【 upper_bound 】 解释,upper_bound递归右子树部分,这里不变
⑤:【 1 】 解释,上面读入二叉树的时候从1开始录入,这个送分题,也是从1开始递归。